Google Drive per ottenere testo editabile tramite OCR
Lo spazio cloud di Google, Google Drive, che dà accesso a Google Documenti (la suite di applicazioni per ufficio sviluppata dall’azienda di Mountain View), dispone di uno strumento OCR (Optical Character Recognition=Riconoscimento ottico dei caratteri) che permette di convertire documenti PDF e immagini (per esempio screenshot, scansioni e fotografie) in file di testo che potremo poi copiare, modificare, editare, sottoporre a ricerca,….
Per prima cosa è necessario creare un account su Google, se ancora non lo abbiamo fatto.
Dopo aver effettuato il login bisogna accedere alla nuova interfaccia di Google Drive (spazio gratuito di 5 GB) e caricare il file che vogliamo convertire tramite l’icona Upload e il comando File…

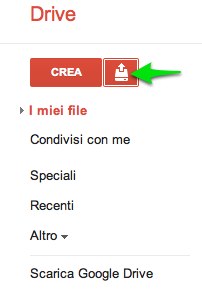
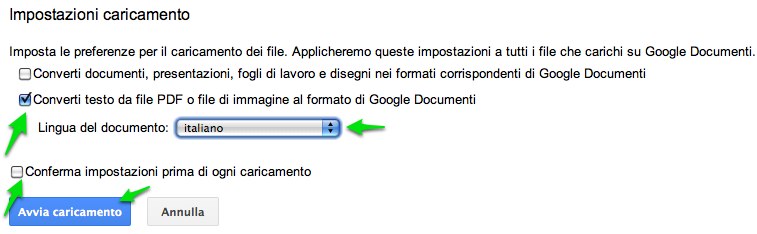
Al momento del caricamento apparirà una finestra di dialogo in cui scegliere le impostazioni di caricamento future. Vistare la seconda opzione (Converti testo da file PDF o file di immagine al formato di Google Documenti) e precisare la lingua del documento da convertire. A seconda delle proprie necessità, attivare o meno Conferma impostazioni prima di ogni caricamento.
Otterremo un file contenente in alto il documento originale e in basso il risultato della conversione.

In ogni momento potremo cambiare le impostazioni di caricamento cliccando sul menu a discesa accanto all’ingranaggio oppure facendo clic sul menu a discesa Impostazioni nella finestra che indica l’avanzamento del caricamento.
Per ottenere risultati migliori, i file di immagine o PDF devono soddisfare determinati requisiti:
- Risoluzione: i file ad alta risoluzione consentono risultati migliori. Se è possibile bisogna fare in modo che ciascuna riga di testo nei documenti abbia un’altezza di almeno 10 pixel.
- Orientamento: vengono riconosciuti solo i documenti con testo orizzontale da sinistra a destra. In caso di documenti con orientamento diverso, si consiglia di utilizzare un programma per ruotare le immagini prima di caricarle.
- Lingua, tipi di carattere e set di caratteri: per ora sono riconosciuti solo i caratteri latini quindi, ad esempio, i testi in giapponese, in arabo o i manoscritti non verranno rilevati. I tipi di carattere comuni come Arial e Times New Roman consentono di ottenere i risultati migliori.
- Qualità immagine: le immagini nitide, luminose con contrasti chiari consentiranno prestazioni migliori. Un’immagine mossa o un’errata messa a fuoco della fotocamera ridurranno la qualità del testo rilevato.
Limiti di dimensione dei file
La dimensione massima per le immagini (.jpg, .gif, .png) e i file PDF (.pdf) è 2 MB. Per i file PDF l’estrazione del testo si concentra solo sulle prime 10 pagine.
Conservazione della formattazione del testo
Durante l’elaborazione del documento, il tool OCR di Google cerca di conservare la formattazione base del testo come il grassetto e il corsivo, la dimensione e il tipo di carattere e le interruzioni di pagina. Tuttavia, il rilevamento di questi elementi è complicato e non sempre sarà possibile ottenere risultati soddisfacenti. Altri elementi di struttura e formattazione del testo come elenchi puntati e numerati, tabelle, colonne di testo e note a piè di pagina o note di chiusura potrebbero essere persi.
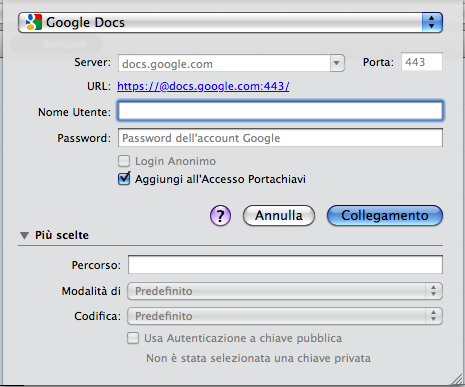
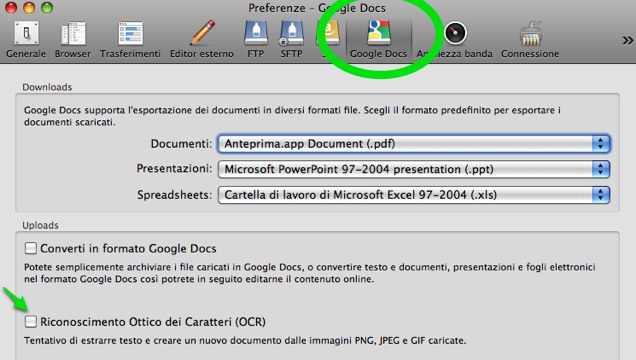
Infine da notare che Cyberduck, freeware gratuito per il trasferimento di file su diversi tipi di server (Cloud, FTP, SFTP, WebDav) e per l’editing dei test, è in grado di caricare documenti anche su Google Drive e nelle sue preferenze offre la possibilità di fare uso dell’OCR di Google Docs.